2023. 9. 11. 00:29ㆍ인공지능(AI)
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection (CVPR 2022)
Abstract
일반적인(prevalent) multimodal 방법[PointPainting, PointAugmenting]들은 단순히 LiDAR point cloud에 카메라 특징을 추가하고 이를 기존 3D detection model에 직접 입력한다.
연구에 따르면 raw LiDAR point 대신 deep lidar feature를 camera feature와 fusion하면 성능이 향상될 수 있을 보였다. 하지만 이러한 feature들은 augmented 및 aggregated 되므로, 어떻게 두 modality간의 변형된 feature를 효과적으로 align할지가 중요하다. 해당 논문에서는 두가지를 제안한다.
1. InverseAug: geometric-related augmentation을 역으로 적용하여 LiDAR point와 Image pixel 간의 정확한 가하학적 align을 가능하게 한다.
2. LearnableAlign: cross-attention을 활용하여 fusion중에 Image와 LiDAR feature 간의 상관관계를 동적으로(dynamically) 포착한다(capture).
Introduction
3D object detection에 있어서, LiDAR는 저해상도의 형태와 depth 정보를 제공하는 반면, camera는 고해상도의 형태와 질감(texture) 정보를 제공한다. 두 센서의 조합으로 최고의 성능을 낼 것으로 보이지만, 대부분 SOTA 모델은 LiDAR만을 입력으로 하고 있으며, 어떻게 효과적으로 fusion할 지는 여전히 challenge에 있다.
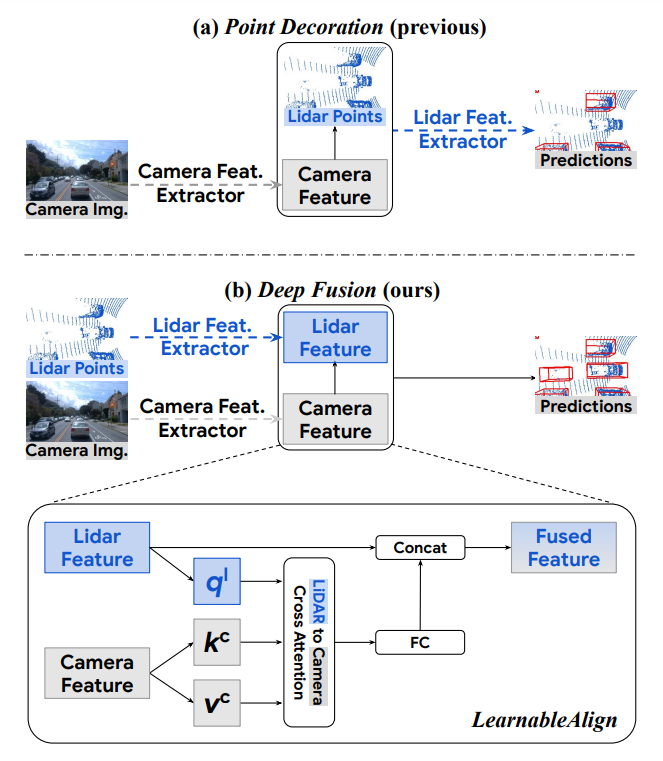
Figure 1을 보면 이전 SOTA 모델들은 camera feature를 raw LiDAR point에 추가해서 사용하고 있고, Deep Fusion은 각각 추출된 feature를 fusion해서 사용하는 것을 볼 수 있음.
기존 fusion 방식은 두 가지가 있는데, 하나는 early stage에서의 fusion, 다른 하나는 mid-level fusion이 있다. Fig 1. (a)에 해당하는 부분이 전자이고, 이 논문에서는 mid-level fusion을 채택한다.
InverseAug는 geometric-related data augmentation을 inverse로 적용하고, original camera와 LiDAR parameter를 사용하여 두 modality를 연관짓는다.
LearnableAlign은 cross-attention을 활용하여 동적으로 LiDAR feature와 대응되는 camera feature의 관계를 학습한다.
align된 multimodal feature를 융합할 때, 높은 해상도를 가진 camera signal은 모델의 recognition 및 localization ability를 크게 향상시키며, 특히 장거리 객체 감지(long-range object detection)에 이점을 가진다.
DeepFusions
(1). end-to-end로 train될 수 있다.
(2). 기존 voxel 기반 3D detection 방법과 호환이 되는 일반적인 구성 요소이다.
Contribution
1. 최초로 3D multimodality detection에 대한 deep feature align의 영향을 체계적으로 연구
2. deep feature level의 align을 달성하기 위해 InverseAug와 LearnableAlign을 제안
3. Waymo Open Dataset에서 SOTA 달성
Related work
3D Object Detection on Point Clouds
Lidar-camera Fusion
Point Decoration Fusion
Mid-level Fusion:
2D와 3D backbone 간의 정보를 공유함으로써 두 modality를 fusion하려고 시도한다.
align이 어려운 이유
1. fusion 단계 이전에 LiDAR point와 camera image에 다양한 데이터 augmentation이 적용됨. 예를 들어 z축을 따라 3D world를 최전시키는 RandomRotation은 일반적으로 LiDAR 포인트에 적용 되지만 카메라 이미지에는 적용할 수 없음.
2. 여러 LiDAR 포인트가 scene에서 동일한 3D voxel로 집계되기 때문에, 하나의 voxel은 여러 camera feature에 대응하며, 이러한 camera feature들은 3D detection에 있어 동등하게 중요하지 않음. [?]
Method
Deep Feature Fusion Pipeline
Impact of Alignment Quality
Boosting Alignment Quality
'인공지능(AI)' 카테고리의 다른 글
| Yolo 관련 공부 (0) | 2023.08.19 |
|---|---|
| Auxiliary Learning (0) | 2023.08.12 |
| [CGAN] Conditional Generative adversarial Nets 논문 공부 (0) | 2023.02.24 |
| [GAN] Generative Adversarial Nets 논문 공부 (1) | 2023.02.19 |